پایتون بهدلیل ویژگیهای قدرتمند و مزیتهای فراوان یکی از پرطرفدارترین زبانهای برنامهنویسی در دنیای دیجیتال است. همانطور که استفاده از پایتون بهعنوان یک زبان برنامهنویسی همه فن حریف در بیشتر پلتفرمها درحال رشد است، وجود پایگاه داده مناسب برای ذخیره و سازماندهی انواع داده، ابزار مهمی برای ساخت برنامههای قدرتمند بهشمار میرود. بهترین دیتابیس برای پایتون با در نظر گرفتن ویژگیهایی مثل مقیاسپذیری، سرعت و پایداری انتخاب میشود. در این نوشته از مجله فرادرس، برخی از بهترین پایگاه دادههای موجود که برای جامعه برنامهنویسان پایتون و همچنین متناسب با کاربردها و ویژگیهای پایتون طراحی شدهاند و پشتیبانی خوبی برای زبان برنامهنویسی پایتون فراهم میکنند را بررسی میکنیم.
صرفنظر از اینکه صفحات وب یا اپلیکیشنهای دسکتاپ را گسترش میدهیم یا اینکه با مواردی همچون پایپلاینهای داده یا سیستمهای پیچیده تحلیل داده کار میکنیم، انتخاب پایگاه داده مناسب با توجه به نیازهای پروژه، کارایی و بازدهی برنامه پایتونی را افزایش میدهد. پس برای شناسایی بهترین دیتابیس برای پایتون باید با آنها آشنا شویم. پایگاه داده، فضای ذخیرهسازی کامپیوتر را منظم، مطمئن و سریع میکند. این مفهوم همچنین به شما چارچوبی ذهنی درباره چگونگی ذخیره و بازیابی دادهها ارائه میدهد تا هر بار به چگونگی استفاده از دادهها هنگام نوشتن برنامهای جدید فکر نکنیم. پایگاههای داده به ۲ دسته اصلی تقسیم میشوند که در ادامه فهرست کردهایم.
- پایگاه دادههای رابطهای SQL
- پایگاه دادههای NoSQL
در «پایگاه دادههای رابطهای» (Relational Databases)، دادهها بهصورت جدولی ذخیره میشوند، بهطوری که جداول میتوانند بههم متصل شده و روابط بین قطعات مختلف دادهای را ایجاد کنند. پایگاه دادههای NoSQL نسبت به پایگاه دادههای رابطهای بسیار منعطفتر هستند. در این نوع از پایگاههای داده، ساختار ذخیرهسازی دادهها برای هدف و نیازمندی خاصی طراحی و بهینهسازی شدهاند.
معرفی بهترین دیتابیس برای پایتون
یکی از مهمترین چالشهایی که هر برنامهنویس بک اند با آن رو بهرو میشود این است که کدام یک از پایگاههای دادهای را باید انتخاب کند. انتخاب پایگاه داده مناسب، تضمین میکند که برنامه پایتونی توانایی مدیریت و ذخیرهسازی دادهها در حجمهای مختلف را بهطور مؤثر داشته باشد. همچنین امکان تهیه گزارش از دادهها را نیز در اختیارمان قرار دهد.

در ادامه، برخی از بهترین پایگاههای دادههای پایتون را بررسی میکنیم که در دسترس برنامهنویسان قرار دارند.
پایگاه داده SQLite
پایگاه داده SQLite در واقع یک سیستم اوپن سورس برای مدیریت پایگاه داده رابطهای است. با توجه به اینکه پایگاه دادهای بسیار ساده، کمحجم و آماده استفاده است بهعنوان یکی از پر کاربردترین و بهترین پایگاه دادههای پایتون محسوب میشود. وجود این پایگاه داده بهصورت کتابخانهی استاندارد در کنار پایتون، استفاده از آن را ساده میسازد.به دلایل کوتاه ذکر شده در متن پایگاه داده SQLite میتواند اولین گزینه بهترین دیتابیس برای پایتون حداقل برای تازهکارها و دانشجویان باشد.
SQLite، دادهها را در پایگاه داده قابل حمل، فشرده و مستقل ذخیره میکند که بهآسانی قابلاشتراکگذاری است. بهدلیل «بدون سرور» (Serverless) بودن، نیازمند تنظیمات خاصی نیست و از طریق فراخوانی توابع ساده با دادهها تعامل میکند. SQLite همچنین یک رابط ساده DB-API را نیز فراهم میکند.
کاربردهای SQLite
در زیر، برخی از کاربردهای این پایگاه داده را فهرست کردهایم البته تنها به همین موارد محدود نمیشوند.
- نمونهسازی (ایجاد پروتوتایپ)
- آزمایش
- دستگاههای «نهفته» (Embedded)
- هر سناریوی دیگری که نیازمند پایگاه دادهای سبک و بدون تنظیمات خاصی باشد.
خصوصیاتی نظیر استفاده آسان و قابل حمل بودن، SQLite را برای اپلیکیشنهای موبایل، مرورگرهای اینترنتی و ابزارهای هوشمندی که از پایتون استفاده میکنند محبوب کرده است.
SQLite بهدلیل کاربری ساده و ویژگیهای بسیار زیادی که دارد بهعنوان یکی از بهترین پایگاه دادههای SQL برای توسعه پایتون در نظر گرفته میشود. یکی از بهترین کتابخانههای پایتون که برای اتصال و مدیریت پایگاه داده SQLite استفاده میشود «SQLite3» است که به شما این امکان را میدهد تا کوئری SQL را بهطور مستقیم درون کدهای پایتونی خود بنویسید. لازم بهذکر است که SQLite بهدلیل «سریالی» (Serialize) بودن عملیات نوشتن کوئریها، هنگام نیاز به همزمانی در برنامه و همچنین در مواردی که اپلیکیشن چندکاربره است، عملکرد ضعیفی دارد.
پایگاه داده MySQL
MySQL به عنوان بهترین دیتابیس برای پایتون، مخصوصا برای استفاده توسط توسعه دهندهگان حرفهای، میتواند انتخاب خوبی باشد. این پایگاه داده رابطهای، اوپن سورس و پرطرفدار است، از SQL استفاده میکند و بهطور معمول برای وب اپلیکیشنهای که نیاز به یکپارچگی عملیاتی دارند انتخاب میشود، همچنین با پایتون بهخوبی کار میکند.
این پایگاه داده از معماری کلاینت-سرور استفاده میکند که شامل یک سرور SQL پردازش «چند نخی» (Multi-Threaded) میشود این ویژگی کارایی MySQL را بهبود میدهد چون بهآسانی میتواند از چند پردازنده بهصورت همزمان استفاده کند. MySQL در اصل با زبانهای C و C++ نوشته شده و بهمرور زمان برای پشتیبانی از سایر پلتفرمها گسترش یافته است. این دیتابیس به عنوان پایگاه داده مورد استفاده اپلیکیشنهای اولیه مشهور شد و همچنان بهصورت گسترده مورد استفاده قرار میگیرد.
در کدهای پایتون، به کمک کتابخانه mysql-connector-python، امکان دسترسی مستقیم به MySQL وجود دارد. در عین حال از مقیاسپذیری و افزونههای اوپن سورس مانند MariaDB سود میبرد.

کاربردهای MySQL
کاربردهای این پایگاه داده شامل مواردی است که در ادامه بیان کرده ایم.
- سیستمهای تجاری
- پلتفرمهای SaaS
- برنامههای سازمانی که برای آنها پشتیبانی از ACID در کنار پارتیشنبندی پایگاه داده ضروری است.
- پروژههای بزرگ
علاوه بر موارد بیان شده، پشتیبانی MySQL از JSON انعطافپذیری آن را افزایش میدهد. در نتیجه بهراحتی میتوان از MySQL در پایتون استفاده کرد. این پایگاه داده برعکس SQLite از اپلیکیشنهای چندکاربره پشتیبانی میکند و برای سامانههای توزیع شده انتخاب مناسبی است. همچنین اگر بهدنبال قابلیتهای تعاملی و پشتیبانگیری حرفهای در کنار سینتکس آسان و نصب بدون دردسر هستید، MySQL یکی از گزینههای خوب پیشروی شماست.
وقتی از پایتون برای دسترسی به دادهها استفاده میکنید به پایگاه دادهای احتیاج خواهید داشت که مجموعه بزرگی از کتابخانههای SQL را فراهم میکند. در این مورد، MySQL گزینههای کمی برای انتخاب پیش روی شما قرار میدهد که در ادامه بهآنها اشاره کردهایم.
- mysqlclient
- mysql-connector-python
- PyMySQL
این کتابخانهها به شما امکان میدهند تا کوئریهای SQL را داخل کدهای پایتون استفاده کنید. که این امکان قابلیتی عالی محسوب میشود چون MySQL کارایی بالایی دارد و ویژگیهای گستردهای برای ذخیره دادهها، پشتیبانگیری، بازیابی دادهها، تکثیر دادهها و امنیت را بهآسانی در کدهای پایتونی شما در اختیارتان قرار میدهد اماباید توجه کنید که این ابزارها بر خلاف SQLite نیاز به نصب دارند.
بهعنوان مثال، در صورتی که بخواهید در کدهای پایتون با استفاده از کتابخانه mysql-connector-python
به MySQL متصل شویم باید ابتدا آن را با دستور زیر نصب کنید.
python -m pip install mysql-connector-python
اما باید بدانیم که MySQL هنگام بهکارگیری عملیات BULK INSERT یا اجرای جستجوی «تماممتن» (Full-Text) عملکرد ضعیفی دارد.
پایگاه داده MariaDB
MariaDB سیستمی برای مدیریت پایگاه داده رابطهای یا RDBMS است که با پروتکل و کلاینتهای MySQL سازگاری دارد. سرور MySQL میتواند بهآسانی و بدون نیاز به تغییر کدها با MariaDB جایگزین شود. این سیستم مدیریتی، «ذخیرهسازی ستونی» (Columnar Storage) را ارائه میدهد. پایگاه دادهی MariaDB در مقایسه با MySQL، پشتیبانی بیشتری از سمت کامیونیتی دارد و توسعه این سیستم بیشتر بر عهده توسعه دهندهگان داوطلب از سراسر جهان است.
پایگاه داده MariaDB علیرغم مدیریت آسانی که دارد بهشدت قابل اعتماد است، این ویژگیها برای یک DBMS مدرن ضروری است تا بتواند توسط اپلیکیشنهای پیشرفته و جدید مورد استفاده قرار گیرد. همزمان که محبوبیت پایتون در فناوریهای مانند هوش مصنوعی و یادگیری ماشین درحال افزایش است، MariaDB به گزینه مناسبی برای سرور پایگاه داده پایتون تبدیل میشود.
یکی از ابزارهای قدرتمند MariaDB برای پایتون، mariadb
نام دارد که بهراحتی با pip نصب میشود. در ادامه نحوه نصب آن را بیان کردهایم.
pip install mariadb
پایگاه داده PostgreSQL
PostgreSQL پایگاه دادهای پیشرفته از نوع «شیء-رابطهای» (Object-Relational) و اوپنسورس است که توانمندیهای SQL را به همراه قابلیت اطمینان و پایداری بالا ارائه میدهد. همچنین بهدلیل محدودیتهای که برای سطر، ستون و جداول دادهها در نظر میگیرد ضمن پشتیبانی از انواع دادهها، عملگرها، توابع مختلف و غیره، کارایی بسیار زیادی را ارائه میدهد. لازم بهذکر است که ساختار این پایگاه داده نیز بهصورت کلاینت-سِروری است. در پایگاه داده PostgresSQL، فایلها و عملگرهای مدیریت ارتباطات را پروسههای Postgres مینامیم.
PostgreSQL دارای طیف وسیعی از ویژگیهای متنوع است که در زیر بهآنها اشاره کردهایم.
- پشتیبانی از زبانهای برنامهنویسی رویهای
- «تریگرها» (Triggers): به رویههای ذخیره شدهای گفته میشود که قابل فراخوانی نبوده و بهصورت خودکار در واکنش به اقدامات Insert , Update و Delete – قبل یا بعد از تراکنش – اجرا میشوند.
- Stored Procedure-ها
- توابع تعریف شده توسط کاربر
- «نماها» (Views): جداول مجازی که با توجه به اجرای کوئریهای کاربر تشکیل میشوند.

کتابخانه یا اَداپتر psycopg2 دسترسی بسیار عالی برای PostgreSQL در پایتون ایجاد میکند. توسعه دهندهگان فریمورک Django – یکی از قدرتمندترین فریمورکهای توسعه بک اند وب اپلیکیشن پایتون – این فریمورک را به عنوان بهترین دیتابیس برای پایتون، البته در ارتباط با جنگو تشخصی دادهاند و این فریمورک را با تنظیماتی برای ادغام با PostgreSQL عرضه کردهاند.
تمرکز توسعهدهندگان این پایگاه داده روی توسعهپذیری، رعایت استانداردها، «پایداری» (Robustness) – توانایی مقاومت در برابر خرابیها و اختلالها – همچنین امکانات عالی با هدف پردازش موازی و انطباق با قواعد ACID آن را برای سیستمهایی با تراکنشهای پیچیده در مقیاسهای بزرگ و تجاری به گزینه مناسبی تبدیل کرده است.
کاربردهای PostgreSQL
برخی از کاربردهای قابل توجه و چشمگیر این پایگاه داده در پایتون را در زیر نام میبریم.
- اپلیکیشنهای محاسباتی بسیار سنگین مانند سامانههای بانکداری
- بازارهای تجارت الکترونیک
- پلتفرمهای اینترنت اشیاء یا IoT
- دادههای جغرافیایی
- اپلیکیشنهای تجزیه و تحلیل دادهها
- پروژههای علمی و تحقیقاتی
- دیتا ساینس
برای اینکه به پایتون این امکان را بدهیم که با پایگاه داده PostgreSQL ارتباط برقرار کند باید درایور مخصوص آن را نصب کنیم که بهطور معمول از درایور psycopg2
برای این منظور استفاده میشود. شما میتوانید با کمک اجرای دستور زیر در خط فرمان این درایور را نصب کنید.
pip install psycopg2
PostgreSQL نسبت به MySQL، پیچیدگی بیشتری در نصب و شروع استفاده دارد. البته که گفته میشود، با توجه به ویژگیهای پیشرفته بیشماری که ارائه میدهد ارزش این دردسر را دارد.
پایگاه داده Oracle
پایگاه داده اوراکل، گستردهترین سیستم مدیریت پایگاه داده رابطهای (RDBMS) در سازمانهای تجاری است. به نسخههای جدید این پایگاه داده مبتنی بر SQL امکان پردازش و ذخیرهسازی دادهها بهصورت ابری هم افزوده شده است. اوراکل یکی از قدیمیترین سیستمهای پایگاه دادهای است که از دهه ۵۰ شمسی (۷۰ میلادی) در دسترس توسعهدهندگان قرار دارد. این پایگاه داده تا امروز قدرت و اعتبار خودش را حفظ کرده و بالاتر از بسیاری از رقبا ایستاده است.
این پایگاه داده قدیمی و قدرتمند، فضای کمتری را اشغال میکند، دادهها را سریعتر پردازش میکند و شامل ویژگیهای مفید جدیدی مانند JSON نیز میشود. اوراکل میتواند همزمان برروی چندین سرور منطقی یا فیزیکی متفاوت قرار گیرد و میلیاردها تراکنش را مدیریت کند و همچنین امنیت بالایی دارد.

اگر از پایتون بهمنظور تولید نرمافزاری مناسب اداره امور تجاری استفاده میکنید که نیازمند توانایی کار با دادههای زیاد و حجیم است اوراکل میتواند انتخاب اول شما باشد. توصیه خود اوراکل این است که از کتابخانه oracledb
استفاده کنیم. با استفاده از دستور زیر میتوانید آن را در پایتون نصب کنید.
pip install oracledb
پایگاه داده MS SQL Server
مایکروسافت، مجموعه ابزار بسیار خوبی را هم بهصورت محلی و هم بهصورت ابری جهت پشتیبانی یکی از بهترین پایگاه دادهها یعنی Microsoft SQL Server فراهم میکند. MS SQL بهعنوان یکی از بهترین پایگاه دادههای پایتون، یک پایگاه داده «چندمدلی» (Multi-Model) است که از دادههای ساختیافته با SQL، «نیمهساختیافته با JSON و «دادههای فضایی» (Spatial Data) پشتیبانی میکند. منظور از دادههای فضایی هر نوع دادهای است که بهصورت مستقیم یا غیرمستقیم به منطقه یا ناحیه جغرافیایی خاصی اشاره کند.
MS SQL Server به اندازه سایر پایگاه دادههایی که در این مطلب بهآنها اشاره کرده ایم، خلاقانه و پیشرفته نیست اما در طول سالها دستخوش اصلاحات اساسی و پیشرفتهای قابل توجهی شده است.
چندین درایور مختلف در پایتون برای MS SQL Server وجود دارد اگرچه مایکروسافت بیشتر به کتابخانه pyodbc تأکید دارد اما روش نصب و استفاده از هر ۲ کتابخانه pyodbc
و pymssql
را در سایت رسمی خود آموزش میدهد که نشان از اعتبار و قدرت کتابخانه pymssql هم دارد. هر دوی این کتابخانهها با استفاده از دستور pip قابل نصب هستند که در زیر بیان کردهایم اما نکات مهمی در پیکربندی این ابزار وجود دارد که در صورت عدم آشنایی قبلی و مناسب با این پایگاه داده بهتر است شیوهنامه مایکروسافت را برای این کار مطالعه کنید.
کتابخانه pyodbc به صورت زیر نصب میشود.
pip install pyodbc
همچنین، کتابخانه pymssql را نیز به کمک دستور زیر میتوانیم نصب کنیم.
pip install pymssql
این مطلب که آیا MS SQL Server میتواند به عنوان بهترین دیتابیس برای پایتون برگزیده شود یا نه ارتباط مستقیم با نوع برنامهای که توسعه دهندهگان در حال طراحی آن هستند، دارد.
پایگاه داده IBM DB2
IBM نرمافزار پایگاه داده DB2 را برای انواع سیستم عاملهای ویندوز، لینوکس و یونیکس عرضه کرده است. DB2 نسخه ۱۱٫۵ جدیدترین نسخه از این سیستم پایگاه داده است، سرعت اجرای کوئریها را بهشدت افزایش داده و از زبان SQL استاندارد برای کار روی دادهها استفاده میکند. مجموعهی پایگاه دادههایی که برای برنامههای موبایل استفاده میشوند بیشتر مدلهای رابطهای را پوشش میدهند. این مجموعه در سالهای اخیر بهصورت قابل توجهی رشد کرده و پایگاه دادههای جدید هم خود را در این مجموعه وارد کردهاند. درحال حاضر این مجموعه بزرگ، ویژگیهای «شی-رابطهای» (Object-Relational) و اشکال غیررابطهای مانند JSON و XML را هم پشتیبانی میکند.
بهگفته IBM پایگاه داده DB2 پایگاه دادهای «ابری» (Cloud-Native) است، که بهمنظور کاهش تاخیر در تراکنش دادهها و افزایش قدرت تجزیه و تحلیل دادهها، در هر مقیاسی ساخته شده است. بهدلیل اینکه شرکت IBM دستی بر آتش تولید پردازشگرها دارد این پایگاه داده، بیشترین هماهنگی را با سختافزار پردازشگر بهوجود آورده است. در نتیجه سرعت بالاتر پردازش را در کنار صرفهجویی بسیار عالی در مصرف پردازشگر بههمراه میآورد. از ویژگیهای این پایگاه داده میشود به امنیت بالا، مقیاسپذیری و دسترسی بسیار عالی اشاره کرد. شما میتوانید از DB2 برای مواردی مانند حفظ امنیت، کارایی بالا و انعطافپذیری برنامهها و تحلیلهایتان در هرجایی استفاده کنید.
IBM همچنین کتابخانه ibm_db
را برای اتصال پایتون به این پایگاه داده معرفی کرده است.
پایگاه داده MongoDB
MongoDB پرطرفدارترین پایگاه داده «سند گرا» (Document-Oriented) و NoSQL است که با «وظایف کاری» (Workloads) مختلف تحلیلی و وب پایتون بهکار میرود. از فایلهایی مانند JSON برای ذخیره دادهها استفاده میکند که این ساختار JSON مانند را BSON مینامند و نمایش روابط سلسلهمراتبی و کارکردن با دادهها را آسان میکند.

«طرحوارههای» (Schema) پویا، کوئرینویسی بسیار قوی و متنوع با عملگرها، «نمایهگذاری» (Indexing) و عملیات «تجمیع پایپلاینها» (Aggregation Pipelines)، MongoDB را بهشدت کارآمد و کاربردی کرده است.
کاربردهای MongoDB
وجود ویژگیهایی که اشاره کردیم باعث شده استفاده از آن در برخی از پلتفرمهایی که در ادامه مثال زدهایم بسیار سودمند باشد.
- OTT-ها
- سرویسهای استریمینگ یا پخش آنلاین محتوای ویدئویی بدون دانلود کامل آنها
- سیستمهای مدیریت محتوا
- سیستمهای نظارتی
- تجزیه و تحلیل دادهها بهصورت آنی
- موتورهای توصیه کننده براساس اطلاعات زمینهای
درایور PyMongo پایتون، دسترسی با زبان استاندارد خود پایگاه داده را درون کدهای پایتون فراهم میکند. فریمورک Flask، بهصورت خاص در پایتون، با تنظیماتی برای ادغام با PyMongo عرضه میشود. MongoEngine یک ORM پایتون است که برای MongoDB در بالای کدهای PyMongo نوشته شده است. برای استفاده از MongoDB شما باید موتور و کتابخانههای موجود و بهروز MongoDB را بهصورتی که در ادامه بیان کردهایم نصب کنید.
pip install pymongo==3.4.0 pip install mongodb
پایگاه داده Redis
Redis بهعنوان یکی از بهترین پایگاه دادههای پایتون، یک نرمافزار ذخیرهسازی ساختارداده، بهصورت «درون حافظه» (In-Memory) و اوپنسورس است که ویژگیهای زیر را بهصورت ذاتی فراهم میکند.
- ذخیرهسازی کارآمد و سرعت بسیار بالا
- سرویس «واسطه پیام» (Message Brokering)
- امکان «محدودسازی نرخ» (Rate Limiting)
این برنامه، دادهها را بهشکل جفتهای «کلید-مقدار» (Key-Value) ذخیره میکند و انواع گوناگون دادهها را مانند رشته، Hash، لیست و مجموعه میپذیرد. این پایگاه داده دسترسی بسیار بالا به دادهها با کمک Redis Sentinel و پارتیشنبندی خودکار را با استفاده از Redis Cluster فراهم میکند. همچنین Redis بهعنوان سریعترین پایگاه داده جهان شناخته میشود. اما این یک پایگاه داده موقت است چون تمام عملیات خود را روی حافظه اصلی یا همان RAM، ذخیره میکند و در صورت خاموش شدن سیستم، رفتن برق یا حتی Crashing حافظه اصلی کامپیوتر کل دادهها از دست میرود. در نتیجه اینکه Redis بتواند بهترین دیتابیس برای پایتون باشد چندان منطقی نیست اما به این دلیل که معمولا بهعنوان یاری دهنده در کنار پایگاه داده اصلی استفاده میشود، هر دیتابیسی که بخواهد عنوان بهترین دیتابیس برای پایتون را نصیب خود کند، حتما باید Redis را در کنار خود داشته باشد.
کاربردهای Redis
توسعهدهندگان نرمافزار در پایتون، Redis را بهطور خاص برای برنامههایی انتخاب میکنند که توان عملیاتی بسیار بالا و زمان پاسخگویی بسیار پایینی لازم دارند. این پایگاه داده اغلب بهطور وسیع در مواردی که در پایین فهرست شده استفاده میشود.
- ذخیرهسازی دادهها بهصورت همزمان با اجرای عملیات در حافظه مرورگر اینترنت، عملیات مربوط به ذخیرهسازی روی فضای رم (Session Store) انجام میشود. توجه کنید بستن مرورگر باعث پاکشدن همه اطلاعات روی RAM میشود.
- پلتفرمهای استریمینگ به معنی پخش آنلاین محتواهای ویدئویی بدون دانلود کامل آنها، که نیاز به سامانه ذخیره سازی داده بسیار سریع دارد.
- کنار گذاشتن دادههایی که قرار است بزودی دوباره استفاده شوند یا به اصطلاح Caching.
- در مواردی که به «جدول امتیازات لحظه ای» (Real-Time Leaderboards) نیاز است.
- در هر اپلیکیشن دیگری که نیازمند دسترسی آنی به دادهها است.
معمولا از Redis در پایتون بهوسیله کتابخانه redis-py استفاده میکنند. این ابزار کار با Redis را بسیار ساده میکند و مورد علاقه بیشتر برنامهنویسان است. که بهآسانی با کد زیر میشود نصب کرد.
pip install redis
پایگاه داده Cassandra
«Apache Cassandra» بهعنوان بهترین دیتابیس برای پایتون، پایگاه داده NoSQL توزیع شدهای است که برای مقیاسپذیری و دسترسیپذیری بالا در سطوح توان عملیاتی و اطلاعات انبوه طراحی شده است. این سیستم مدیریت حافظه از مدل دادهای ستونی (Columnar Data) استفاده میکند که اجازه میدهد «طرحواره»های (Schema) مختلف بهسرعت شکل بگیرند و تکامل پیدا کنند. این پایگاه داده، زبان استاندارد کوئرینویسی خود را دارد که مشابه SQL است و CQL نامیده میشود، این اصطلاح مخفف Cassandra Query Language است.

درایورهایی مانند pyCassa به پایتون کمک میکنند که با Cassandra ادغام شود. با اینکه Cassandra در نصب و شروع استفاده دارای پیچیدهگیهایی است اما بههرحال با دنبال کردن راهنمای نصب در وبسایت رسمی Cassandra میتوانید بهخوبی اینکار را انجام دهید. مدل سیستم توزیع شده، بدون کامپیوتر سرور در یک شبکه کامپیوتری یا «بدون ارباب» (Masterless) بهعلاوه سطوح «سازگاری قابل تنظیم» (Tunable Consistency) آن را برای اپلیکیشنهایی که با کلان دادهها کار میکنند برجسته میکند.
سطوح سازگاری قابل تنظیم در پایگاه داده Cassandra چیست؟
سطوح «سازگاری قابل تنظیم» (Tunable Consistency) در Cassandra را میتوانیم بهصورت مختصر و مفید به این صورت توضیح دهیم، بهدلیل اینکه معماری پایگاه داده Cassandra بهصورت Masterless است و بار کاری روی سرورهایی پخش میشود که بهصورت منطقی و فیزیکی جدا از هماند، سرورها مانند گرههایی با ارزش یکسان در فضای گرافی باهم کار میکنند. از اطلاعات بهصورت تنظیم شده روی سرورهای مختلف کپی تهیه شده و هر درخواستی که از کلاینتها میآید توسط سرورهای گوناگون بهصورت موازی پاسخ داده میشود،
صحت پاسخ در کنار سلامت دادهها چک میشود و پاسخ صحیح به کاربر برگردانده میشود. تعداد کپیهایی که از داده، بهصورت موازی نسبت بهدرخواست کاربر عکسالعمل نشان میدهند قابل تنظیم است. به این فرایند «سازگاری قابل تنظیم» (Tunable Consistency) میگویند و تاخیر در زمان پاسخدهی را کمی افزایش میدهد اما صحت پاسخ را تضمین و آمار خرابی در دادهها را به صفر میرساند.
کاربردهای Cassandra
Cassandra چون کارایی بلادرنگ با ثباتی را ارائه میدهد، بهطور ویژه برای ذخیره و بازیابی داده در سیستمهایی با مقیاس حجیم مانند مواردی که در ادامه اشاره شده کاربرد دارد.
- شبکههای اجتماعی
- پلتفرمهای اشتراکگذاری رسانه
- سیستمهای تجزیه و تحلیل IoT
بهطور کلی کاربردهای این پایگاه داده شامل سیستمهایی است که با کلان دادهها کار میکنند مانند موارد بیان شده در بالا یا هر سیستمی که در آن توان عملیاتی روی دادهها و «مقاومت در برابر خطا» (Fault Tolerance) حیاتی است. Cassandra در سیستمهای چندکاربره، تاخیر کمتری در پاسخگویی دارد، علاوه بر این مدیریت امنیتی قدرتمندی که دارد باعث میشود برای هماهنگی با اپلیکیشنهای کشف تقلب نیز عالی باشد.
پایگاه داده DynamoDB
Amazon DynamoDB بهعنوان بهترین دیتابیس برای پایتون، پایگاه دادهای کاملا مدیریت شده، ابری و NoSQL بهشمار میرود که توسط شرکت خدمات وب آمازون یا AWS طراحی شده است. «کاملا مدیریت شده» (Fully Managed) است به این معنا که تمامی جنبههای عملیاتی، نگهداری، پشتیبانی و مدیریت آن توسط سرویسدهنده ارائه میشود و کاربر نیازی به مدیریت و نگهداری آن ندارد. این پایگاه داده کارایی بسیار بالایی دارد و تاخیر پاسخگویی چند میلیثانیهای در هر مقیاسی ارائه میدهد. پشتیبانی از دو مدل ذخیره داده «داکیومنت گرا» (Document-Oriented) و «کلید-مقدار» (Key-Value)، آن را بسیار انعطافپذیر کرده است.
API مربوط به Boto3، پایگاه داده DynamoDB را با اپلیکیشنهای ابری پایتون یکپارچه میکند. مزیتهای خوبی مانند مواردی که در زیر فهرست کردهایم، این پایگاه داده را برای سیستمهای اصلی و حیاتی سازمانها ایدهآل کرده است.
- «تنظیم خودکار ظرفیت» (Auto-Scaling Capacity)
- ذخیرهسازی SSD
- جداول عمومی
- امنیت
- «پشتیبانگیری» (Backup) و بازیابی اطلاعات
کاربردهای DynamoDB
برخی از رایجترین موارد استفاده پایگاه دادهی DynamoDB را در ادامه آوردهایم.
- اپلیکیشنهای بدون سرور
- بک اند برنامههای موبایل
- خدمات وب توزیع شده در مواردی که استحکام و راحتی پایگاه دادههای ابری علت اصلی انتخاب آنهاست.

پایگاه داده Elasticsearch
Elasticsearch بهعنوان بهترین دیتابیس برای پایتون، شباهت زیادی با پایگاه دادههای سنتی ندارد و در واقع موتور جستجو و تحلیل داده اوپنسورس مشهور و پرطرفداری بهشمار میرود که روی کتابخانه موتور جستوجوی Apache Lucene – که اولین بار در سال ۱۳۸۹ (سال ۲۰۱۰ میلادی) توسط آقای «شای بانن» معرفی شد – ساخته شده است. با کمک آن میتوانید حجم بزرگی از دادههای آنی را جمعآوری، پردازش، ذخیره، تحلیل و مصورسازی کنید. همچنین میتواند با انواع دادهها از قبیل دادههای ساختیافته و بدون ساختار، متنی، عددی و جغرافیایی کار کند.
با اینکه Elasticsearch همانطور که اشاره کردیم در واقع یک پایگاه داده سنتی نیست اما پشتیبانی از نمایهگذاری و کوئرینویسی دادههای نیمهساختیافته در هر مقیاسی آن را به گزینهای بسیار با ارزش برای اپهای دادهای پایتون تبدیل کرده است. امکانات بسیار جالبی مانند آنالیز متن به الستیک سرچ این قابلیت را میدهد که علاوه بر جستجوی دقیق عبارت، عبارات مرتبط با عبارت وارد شده که احتمالاً مورد نظر کاربرد بوده را نیز پیدا کند.
کاربردهای Elasticsearch
کلاینت رسمی الستیک پایتون امکان استفاده از کاربردهایی مانند موارد فهرست شده در زیر را بهآسانی فراهم میکند.
- جست و جو
- تحلیل Log-ها
- هوش تجاری
- عملیات نظارت دادهها
در پایتون بهوسیله کتابخانه elasticsearch
میتوان با Elasticsearch ارتباط برقرار کرد. همچنین بستهای برای پایتون بهنام elasticsearch-py
موجود است که به توسعهدهندگان پایتون رابطکاربری سادهای ارائه میدهد. Schema-Less است به این معنی که نیاز ندارد پیش تعریفی از طرحواره یا ساختار داده داشته باشد و این مساله ذخیره و جست و جو در دادههای بدون ساختار را برای آن آسان کرده است.
پایگاه داده Neo4j
پایگاه دادهای مبتنی بر گراف، محبوب، رایگان و NoSQL است که از ابتدا برای کار با دادهها و روابط بین آنها در سال ۱۳۸۶ (۲۰۰۷ میلادی) ساخته شد. Neo4j برروی دادههای بهشدت متصل و جست و جو در روابط پیچیده متمرکز شده است. پردازش و ذخیرهسازی گراف آن را برای نقاط داده متصل بهم، بهینه کرده است. Neo4j دادهها را همزمان با ذخیره شدن بههم متصل و امکان جستوجوی بین دادهها با سرعت بالا را فراهم میکند.
Neo4j در اصل بهوسیلهی Java و Scala ساخته شده و سپس برای استفاده روی پلتفرمهای گوناگون مانند پایتون توسعه یافته است، همچنین یکی از بهترین وبسایتها با مستندات تکنیکی را دارد که بهطور شفاف و خلاصه همه سوالاتی که ممکن است شما درباره نصب، شروع به استفاده و کاربرد کتابخانه مربوطه داشته باشید را پوشش میدهد.
درایور پایتون Neo4j به اپهای پایتون اجازه میدهد تا همهی دادهها در زمینه گرافهای اجتماعی، توصیهها، AI، یادگیری ماشین و تحلیلهای پیچیده را بهعنوان گره و رابطههای بین گرهها مدلسازی کند. زبان کوئرینویسی Cypher امکانات کاربر پسندی برای جست و جو در گرافها فراهم میکند. این زبان از SQL الهام گرفته شده و به شما کمک میکند دادههای مورد نظر خود را از گراف با دقت کامل استخراج کنید. در وبسایت پایگاه داده Neo4j به این زبان لقب کارآمدترین و گویاترین روش توضیح کوئریهای رابطهای داده شده است.
کاربردهای Neo4j
Neo4j بهطور گسترده برای مواردی که در ادامه اشاره کردهایم کاربرد دارد.
- شبکهسازی اجتماعی
- «مدیریت دسترسیها» (Access Management)
- تشخیص هویت
- کشف تقلب
- بهینهسازی زنجیره تامین مانند دادهها،محصولات و غیره
این سیستم همچنین بهمنظور تحلیل و مصورسازی شبکه بههمراه کارآیی آن یا طراحی و تحلیل سیستمهای توصیهگر، گزینه مناسبی محسوب میشود.
پایگاه داده OrientDB
OrientDB پایگاه دادهای اوپنسورس، چند مدلی و NoSQL است. این پایگاه داده توسعه یافته توسط Java، کسبوکارها را قادر میسازد تا از قابلیتهای نرمافزار مدیریت پایگاه داده گرافی استفاده کنند. بدون اینکه مجبور باشند سیستمهای جداگانهای برای مدیریت کردن انواع مختلف داده بسازند.
«چند مدلی» (Multi-Model) یعنی از انواع مدلهای نگهداری از دادهها در فضای ذخیرهسازی مانند «گراف» (Graph)، «سند» (Document)، «کلید-مقدار» (Key-Value) و مدلهای «شی» (Object) پشتیبانی میکند، هرچند روابط پایگاه داده، مانند گراف با روابط مستقیم بین رکوردها مدیریت میشوند.
این یک راهحل مدیریتی محسوب میشود که پایگاه داده OrientDB با پشتیبانی از انواع مدلها مانند گراف، سند، کلید-مقدار و شیگرایی، کارایی و امنیت را افزایش میدهد در حالی که امکان مقیاسپذیری را هم فراهم میکند. به همین دلیل است که وبسایت رسمی این پایگاهداده، OrientDB را بهعنوان پایگاه داده آینده معرفی میکند. در سایت رسمی OrientDB نوشته شده که این پایگاه داده میتواند ۱۲۰۰۰۰ داده را در هر ثانیه ذخیره کند، پیمایش تمامی درختها یا گرافهای رکوردها در طی چند میلی ثانیه انجام میشود و اندازه پایگاه داده تاثیری در سرعت پیمایش ندارد.
در ادامه نموداری آوردهایم که راهاندازی ابتدایی پایگاه داده OrientDB را نشان میدهد.
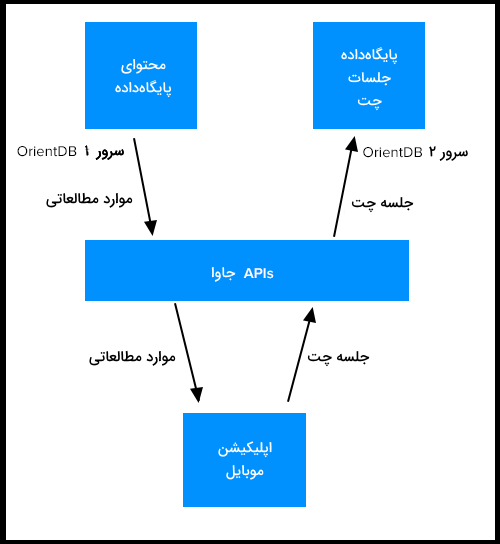
کاربردهای OrientDB
چند مورد از کاربردهای OrientDB را بهصورت زیر فهرست میکنیم.
- امور مربوط بانکداری
- تجزیه و تحلیل و عملیات روی کلاندادهها
- برنامههای کشف تقلب
- شبکههای اجتماعی
- سامانههای مدیریت ترافیک
با استفاده از ماژول PyOrient در پایتون شما میتوانید برنامههای پایگاه داده را با OrientDB توسعه بدهید. این ماژول با pip قابل دانلود و نصب است. در سایت OrientDB برای شروع کار و استفاده ازین پایگاه داده راهنمای کاملی قرار داده شده است.
پایگاه داده Couchbase
Couchbase پایگاه دادهای مبتنی بر سند، NoSQL و اوپنسورس است که برروی مقیاسپذیری، در دسترس بودن و کارایی در هر اندازهای متمرکز شده است. از مدل داده JSON استفاده میکند و اجرای عملیات روی دادهها را شبیه به SQL بهوسیله N1QL پشتیبانی میکند. از تواناییهای این پایگاه داده میشود به انعطافپذیری در پذیرش دادهها، مقیاسپذیری بدون مشکل و کارایی بالا بهصورت دائمی و پایدار، اشاره کرد.
Couchbase ترکیبی از ۲ تکنولوژی محبوب NoSQL است در ادامه بیان کردهایم.
- Membase: سامانه مدیریت پایگاه دادهی کلید-مقدار، توزیع شده و اوپنسورس است، که برای نگهداری داده برنامههای وب بهینهسازی شده. فناوری Memcached بهعنوان یک فناوری با عملکرد بالا امکاناتی مانند «پایداری» (Persistence)، «تکثیر» (Replication) و «شاردینگ» (Sharding) را فراهم میکند.
- CouchDB: در بین پایگاه دادههای داکیومنتگرا که برپایه JSON هستند پیشرو است.
کیت توسعه نرمافزار پایتون Couchbase، ذخیره و بازیابی داده را با کمترین تاخیر در برنامههای پایتون ممکن میکند. این پایگاه داده در صفحات وب تعاملی و برنامههای موبایلی که ملزم به مقیاسپذیری انعطافپذیر هستند عملکرد بسیار عالی دارد.

دلایل استفاده از پایگاه داده در پایتون چیست؟
پایگاه دادهها قسمتی جدانشدنی از عملیات تولید و توسعه هر وبسایت یا اپلیکیشن اینترنتی هستند. مهمترین معیار برای انتخاب پایگاه داده نوع و اندازه دادهها و نوع عملیاتی است که ما میخواهیم روی دادهها اجرا کنیم. در ادامه دلایل اصلی ضرورت استفاده از انواع پایگاههای داده را در کنار پایتون بررسی خواهیم کرد.
ماندگاری داده ها
پایگاه دادهها «ماندگاری» (Persistence) حافظه و امکان بازیابی دادهها را بعد از چرخه عمر اجرای نرمافزار فراهم میکنند. در نتیجه بهصورت طولانیمدت، چندین بار متوالی دادهها مورد استفاده قرار میگیرند و کار توسعهدهندگان و تحلیلگران داده را آسانتر میکنند.
حافظه ساختارمند
پایگاه دادهها ساختار منظم و سازماندهی را برروی دادههای نامنظم اعمال میکنند و باعث میشوند تحلیل و اجرای عملیات بر روی دادهها آسانتر شود. بهخاطر سازماندهی بسیار دقیق و موشکافانه است که روابط بین دادهها را قابل مدلسازی اند.
مقیاس پذیری
بهکمک پایگاه دادهها کاربر میتواند حجم دادههای بزرگ و درحال رشد را با استفاده از ویژگی «مقیاسپذیری» (Scalability) و ترافیک دادهها را با کمک پارتیشنبندی (Sharding) و تکثیر مدیریت کند. این خصوصیات باعث میشود پایگاه دادهها برای سیستمهای تولیدی عالی باشند.
کنترل دسترسی
محافظت در مقابل حملات سایبری از مهمترین مفاهیمی است که در حوزه کامپیوتر از آن بهره میگیرند. حتی یکبار نفوذ در دادهها هم میتواند منجر به نشت اطلاعات حساس و آسیب شدید به اعتبار شرکت یا سازمانهای مختلف شود. بنابراین محدود کردن دسترسیهای خاص به پایگاهداده برای افراد مشخص و اجرای قوی مکانیزم «کنترل دسترسی» (Access Control) میتواند از اطلاعات حساس ذخیره شده در پایگاهداده محافظت کند. مجوزها و کنترل پیچیده دسترسی کاربران را میشود برای اشتراکگذاری دادهها با کاربران خاص و امنیت برنامهها روی پایگاه داده اعمال کرد.
یکپارچه سازی
کتابخانهها و درایورهای خوبی وجود دارند که پایگاه دادههای پرطرفدار و مشهور را بهصورت شفاف و کارآمد با پایتون یکپارچه میکنند و متعاقبا شما میتوانید بهآسانی دادههارا ذخیره کنید یا بخوانید.
قابلیت های تحلیلی
تحلیل دادهها مربوط به تجزیه و تحلیل کارایی وبسایت شماست. پایگاه دادههای SQL شامل قابلیتهای جستوجو، مجتمعسازی و تجزیه و تحلیل قدرتمندی هستند. این پایگاه دادهها بهکمک این ابزار آماده اقدام به فعالیت برای پیداکردن درکی درست از وضعیت و افزایش کارایی و راندمان سایت شما میباشند.
نیرومندی
همه پایگاه دادهها، از اطلاعات در مقابل خرابی برنامهها و سختافزار محافظت میکنند. و این محافظت را بهکمک عملیات بکاپ/بازیابی، تکثیر و «تعمیر خودکار خرابیها» (Automatic Failover) را انجام میدهند. این مسأله، ازدست نرفتن دائمیدادههای حیاتی را در موارد «خرابیهای ناگهانی» (Emergency Failure) تضمین میکند.
سوالات متداول
تا اینجا با بهترین دیتابیسهای پایتون آشنا شدهایم. در ادامه، با برخی از مهمترین سوالات متداول پیرامون این موضوع آشنا میشویم.
بهترین دیتابیس برای پایتون چیست؟
این پرسش که بهترین دیتابیس برای پایتون کدام است پاسخ واضحی ندارد. در واقع، مهمترین عامل برای انتخاب بهترین دیتابیس برای پایتون بههنگام برنامهنویسی، توجه به نوع دادهها و عملیاتی است که روی دادهها انجام میدهیم. اما میتوان از پایگاه دادههایی مانند MySQL ،PostgreSQL ،SQLite ،MongoDB ،Redis و اوراکل به عنوان بهترین دیتابیسهایی که امکان ادغام بدون خطا با پایتون دارند همچنین برای پایتون ابزار خوبی برای دسترسی و عملیات روی دادهها فراهم میکنند، نام برد.
آیا SQLite از MySQL بهتر است؟
MySQL سیستم مدیریت کاربر با ساختار مناسب دارد که میتواند کاربران متعددی را مدیریت و سطوح مختلف مجوز را بهآنها اعطا کند. در مقابل، SQLite برای پایگاه دادههای کوچکتر مناسب است و همچنین دردسرهای مربوط به نصب و پیکربندی در پایتون را ندارد.
جمعبندی
امکانات گسترده پایتون برای ادغام با پایگاههای داده این اجازه را به توسعهدهندگان میدهد که با توجه به نیازمندیهای اپلیکیشن، زیرساخت مناسب را برای ذخیرهسازی و بازیابی دادهها انتخاب کنند. انتخاب پایگاه داده متناسب با حجم داده و نوع برنامه شما میتواند زمان توسعه برنامه را کاهش دهد درحالی که بازده آن را افزایش میدهد. به عنوان پرطرفدارترین پایگاه های داده برای پایتون، میتوان از MySQL, PostgreSQL, MongoDB, Redis و SQLite نامبرد. هر کدام ازین پایگاه های داده مزایایی مثل مقیاس پذیری (تقریبا بجز SQLite)، پایداری، کارآمدی و سازگاری آسان با پایتون (بهخصوص SQLite) را ارائه میدهند.
در این مطلب از مجله فرادرس بررسی کردیم که بهترین دیتابیس برای پایتون با توجه به ویژگیهای هر دیتابیس و نیازهای ما کدام موارد میتوانند باشند و ضمن معرفی، ویژگیها و قابلیتهای هریک را بیان کردیم. یک توسعهدهنده حرفهای حتما باید نسبت به محصول تولیدی خود و نیازمندیهای برنامه اشراف داشته باشد تا با بررسی کامل دیتابیسها بهترین دیتابیس برای پایتون را با توجه به نیاز پروژه شناسایی کند.
source